SPSS Statistics26破解版是一款专业的一体化统计分析解决方案,使用旨在为用户提供最齐全和简单的统计分析功能和工具,借助于软件,用户可以快速进行描述统计、回归分析、高级统计等等。并且只在单一工具中即可创建可立即发布的图表、表格和决策树。SPSS 具有
SPSS Statistics26破解版是一款专业的一体化统计分析解决方案,使用旨在为用户提供最齐全和简单的统计分析功能和工具,借助于软件,用户可以快速进行描述统计、回归分析、高级统计等等。并且只在单一工具中即可创建可立即发布的图表、表格和决策树。SPSS 具有完整的数据输入、编辑、统计分析、报表、图形制作等功能。此外,它还能够读取及输出多种格式的文件。比如由dBASE、FoxBASE、FoxPRO产生的*.dbf文件,文本编辑器软件生成的ASCⅡ数据文件,Excel的*.xls文件等均可转换成可供分析的SPSS数据文件。能够把SPSS的图形转换为7种图形文件。结果可保存为*.txt, word, PPT及html格式的文件。与其他同类型的软件相比,首先本软件具有中文界面,这就非常具有明显优势了,界面也是十分的清晰简单,大家可以轻松进行分析操作,不管是初学者、熟练者及精通者都比较适用。你只需要稍加练习就能够掌握简单的操作分析,所以软件在调查统计行业、市场研究行业、医学统计、政府和企业的数据分析应用中得到广泛的应用。非常适合自然科学、技术科学、社会科学的各个领域。本次带来最新20破解版,有需要的朋友不要错过了!
安装破解教程
1、下载并解压,双击SS_CLIENT_64-BIT_26.0_M_W_M.exe运行,稍等一会儿
2、勾选我接受许可协议中的条款,点击下一步
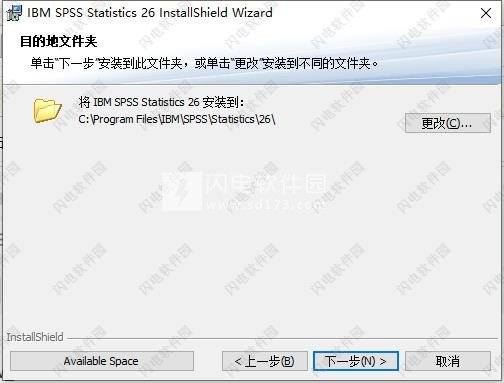
3、点击更改选择软件安装路径,点击下一步
4、继续根据提示进行安装,如图所示,安装完成,退出向导
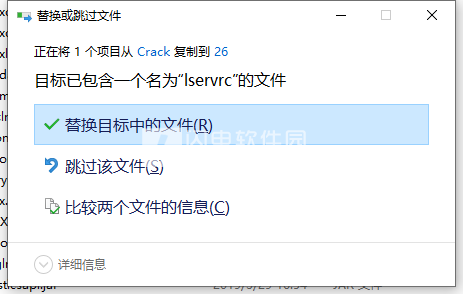
5、将crack中的lservrc复制到安装目录中,点击替换目标中的文件
功能特色
1、全面的统计工具
在一体化的集成界面中工作,运行描述统计、回归分析、高级统计等等。在单一工具中即可创建可立即发布的图表、表格和决策树。
2、与开放源码集成
通过专门扩展,利用 R 和 Python 增强 SPSS Syntax。利用我们的扩展中心提供的 130 多项扩展,或者构建您自己的扩展并与同行共享,以创建个性化解决方案。
3、轻松进行统计分析
使用简单的拖放界面来访问各种功能,并跨多个数据源工作。此外,灵活的部署选项支持您轻松购买和管理软件。
4、数据准备
轻松识别无效值,查看缺失数据的模式,汇总变量分布,并使用为名义属性设计的算法。
5、查看定价并购买
创建更可靠的模型,测试其稳定性,并可靠地估计人口参数的标准误差和置信区间。
6、高级统计信息
分析具有唯一特征的数据,描述因变量和自变量之间的关系,并分析事件历史记录和持续时间数据。
7、回归
预测包含多个类别的分类结果,构建非线性关系模型,并从数十种可能性中找到最佳预测变量。
8、定制表格
汇总相关数据,以演示质量的生产就绪型表格呈现分析结果。您还可以将结果导出到 Microsoft® Office 应用程序中。
9、缺失值
检查数据,发现缺失的数据模式,然后通过统计算法估算汇总统计并插补缺失值。
10、类别
直观呈现并探索复杂的分类、数字和高维数据,并使用双标图、三标图和感知图来揭示隐藏的关系。
11、复杂样本
通过将样本设计融入至调查分析中,计算复杂样本设计中的统计信息和标准误差。
12、联合分析
通过基于单独的特性对消费者的决策流程和价值进行建模,更准确地了解消费者的喜好、权衡取舍及价格敏感性。
13、准确测试
分析数据库中的偶发事件,或更准确地使用少量样本。30 余项准确测试有助于分析导致传统测试失败的数据。
14、预测
无论数据集大小或变量数目多少,都能快速可靠地预测未来状况,同时高效地更新和管理预测模型。
15、决策树
创建分类和决策树,帮助您更好地识别群组、发现各个群组之间的关系,并预测未来事件。
16、直接营销
执行最近购买时间、购买频率和总购买金额 (RFM) 及集群分析、潜在客户概要分析、邮政编码分析、倾向性评分和控制包测试。
17、神经网络
探究数据中微妙或隐藏的模式,发现数据中更复杂的关系,进而生成性能更佳的预测模型。
IBM SPSS Statistics 26 新功能
1、分析过程
对一组预测变量(自变量)与目标变量(因变量)的特定百分位数(即“分位数”,通常是中位数)之间的
关系建模。有关更多信息,请参阅分位数回归
分位数回归并不会假设目标变量的分布,它趋向于抑制偏离观测值的影响,并广泛用于生态、保健和金融
2、Roc分析
用电)般析续关知)与反曲生图使发克
且或成对主体生成的两个ROC曲线。有关更多信息,请参阅ROC分析
3、贝叶斯统计
单向重复测量 ANOVA
这个新过程按每个不同的时间点或条件测量同一个主体的一个因子,并允许这些主体在多个级
别内交叉。假定每个主体针对每个时间点或条件都进行单次观察(因此,不考虑主体处理交
4、单样本二项”增强功能
此过程提供用于对二项分布执行贝叶斯单样本推论的选项。有关参数为π,它表示可能导致成功
或失败的固定数量的试验中的成功概率。请注意,每个试验相互独立,并且概率π在每个试验中
保持相同。二项随机变量可被视为固定数量的独立 Bernoulli试验的总和。
5、单样本泊松增强功能
此过程提供用于对泊松分布执行贝叶斯单样本推论的选项。泊松分布(一种针对罕见事件的有
模型)假设在较小时间间隔内,半件发生的概率与等待时间的长度成比例,在得出对泊松分
布的贝叶斯统计推论时,将使用伽玛分布族中的共轭先验。
6、可靠件分析
过程已进行更新,现提供Fles多评分者 Kappa統计选项,这些选项评估评分者间一致性,以确定各种
评分者之间的可性。该一致性越高,评分反映实情况的置信度也越高。 Fleiss多评分者 Kappa选项
7、命令增强功能
1)MATRIX-END MATRIX命令
·可以使用长变量名称(限长64个字节)来命名矩阵或向量(例如, COMPUTE、cALL、 PRINT
READ、 WRITE、GET、SAVE、MGET、 MSAVE、 DISPLAY、 RELEASE,等等),
·包括在向量或矩阵对象中的变量名称将截断为8个字节。这是因为,矩阵向量结构是数值数组,每个
数值只能与最长B个字节的字符串匹配,只有在明确指定时,才支持长名称(最多64个字节)
·在GET和SAVE命今的/ VARIABLES子命令上明确指定时,以及在SAVE命令的/ STRINGS子命令
上指定时,支持长变二名称,在/ NAMES子命令中通过向黑来引用GET和SAVE命令的变二名称时
这些名称将截断为8个字节
GET、SAVE、MGET或 MSAVE语句同时支持数据引用和指定物理文件
· MATRIX-END MATRIX现在支持以前仅受 COMPUTE命令支持的統计函数(例如,工DF, CHISQ
cDF, NORMAL、 NCDF. F,等等)
2)GENLINMIXED命令
·新的协方差类型结构ARH1和csH-随机效应。在/RAND0M子命令上,已添加csH和ARH1选项(关
键字 COVARIANCE TYPE
新的协方差类型结构ARH1和csH-复效应。在/ DATA STRUCTURE子命令上,已添加CSH和
ARH选项(关键字 COVARIANCE TYPE)
MATRIX- END MATRIX现在支持以前仅受 COMPUTE命令支持的统计函数(例如,IDF, CHISQ
cDF, NORMAL、NCDF.F,等等)
3)GENLINMIXED命今
·新的协方差类型结构ARH和cSM-随机效应。在/RAND0M子命令上,已添加csH和ARH1选项(关
键字 COVARIANCE TYPE)
·新的协方差类型结构ARH1和csH-复效应。在/ DATA STRUCTURE子命令上,已添加csH和
ARH1选项(关键字 COVARIANCE TYPE)
· Kenward- Roger自由度方法,在/ BUILD_0 PTIONS子命令上,已添加 KENYARD ROGER选项(关
键字 DF METHOD)
· Kronecker协方差类型。在/ DATA STRUCTURE子命令上,已添加UNAR1、UNcs和UNWN选项
(关键字 COVARIANCE TYPE)
·新增的 KRONECKER MEASURES关键字。此关键字用来为/ DATA STRUCTURE子命令指定列变
显。仅当c0 VARIANCE TYPE是三种 Kronecker类型之一时,才应使用此关键字。
KRONECKER MEASURES的规则与 REPEATED MEASURES相同。这两个指定项都生效时,它们可能
有也可能没有公共字段,但不能完全相同(无论其顺序是否相同)
4)MIXED命今
·在 CRITERIA子命令上,已引入 DFMETHOD关键字。
REPEATED子命令上,已添加 KRONECKER关键字。仅当 COVTYPE是下列三种 Kronecker类型之
一时,才应使用此关键字。
在 REPEATED子命令的 COVTYPE关键字上,已添加UN_AR1、UN_cs和UNWN选项。
8、INSERT HIDDEN功能
您可在“生产设施”命令行界面中使用 INSERT HIDDEN功能,以将作业提交至 SPSS Statistics Server
通过将“生产设施”命令行界面与 Microsoft
s Task Scheduler,/ Macos automator配合使用以调度
作业,可以有效换 IBM SPSS Collaboration and Deployment Services来处理 SPSS Statistics作业
使用帮助
数据文件管理
1、创建一个数据文件
数据文件的创建分成三个步骤:
(1)选择菜单 【文件】→【新建】→【数据】新建一个数据文件,进入数据编辑窗口。窗口顶部标题为“PASW Statistics数据编辑器”。
(2)单击左下角【变量视窗】标签进入变量视图界面,根据试验的设计定义每个变量类型。
(3)变量定义完成以后,单击【数据视窗】标签进入数据视窗界面,将每个具体的变量值录入数据库单元格内。
2、读取外部数据
当前版本的SPSS可以很容易地读取Excel数据,步骤如下:
(1)按【文件】→【打开】→【数据】的顺序使用菜单命令调出打开数据对话框,在文件类型下拉列表中选择数据文件。
(2)选择要打开的Excel文件,单击“打开”按钮,调出打开Excel数据源对话框。
对话框中各选项的意义如下:工作表 下拉列表:选择被读取数据所在的Excel工作表。
范围 输入框:用于限制被读取数据在Excel工作表中的位置。
3、数据编辑
在SPSS中,对数据进行基本编辑操作的功能集中在Edit和Data菜单中。
4、SPSS数据的保存 SPSS数据录入并编辑整理完成以后应及时保存,以防数据丢失。保存数据文件可以通过【文件】→【保存】或者【文件】→【另存为】菜单方式来执行。在数据保存对话框中根据不同要求进行SPSS数据保存。
5、数据整理
在SPSS中,数据整理的功能主要集中在【数据】和【转换】两个主菜单下。
(1)数据排序(Sort Case) 对数据按照某一个或多个变量的大小排序将有利于对数据的总体浏览,基本操作说明如下:
选择菜单【数据】→【排列个案】,打开对话框
(2)抽样(Select Case)
在统计分析中,有时不需要对所有的观测进行分析,而可能只对某些特定的对象有兴趣。利用SPSS的Select Case命令可以实现这种样本筛选的功能。以SPSS安装配套数据文件Growth study.sav为例,选择年龄大于10的观测,基本操作说明
(3)增加个案的数据合并(【合并文件】→【添加个案】) 将新数据文件中的观测合并到原数据文件中,在SPSS中实现数据文件纵向合并的方法如下:
选择菜单【数据】→【合并文件】→【添加个案】,如图2.11,选择需要追加的数据文件,单击打开按钮,弹出Add Cases对话框
(4)增加变量的数据合并(【合并文件】→【添加变量】) 增加变量时指把两个或多个数据文件实现横向对接。例如将不同课程的成绩文件进行合并,收集来的数据被放置在一个新的数据文件中。在SPSS中实现数据文件横向合并的方法如下:
选择菜单【数据】→【合并文件】→【添加变量】,选择合并的数据文件,单击“打开”,弹出添加变量。
单击Ok执行合并命令。这样,两个数据文件将按观测的顺序一对一地横向 合并。
(5)数据拆分(Split File)
在进行统计分析时,经常要对文件中的观测进行分组,然后按组分别进行分析。例如要求按性别不同分组。在SPSS中具体操作如下:
选择菜单【数据】→【分割文件】,打开对话框
选择拆分数据后,输出结果的排列方式,该对话框提供了3种方式:对全部 观测进行分析,不进行拆分;在输出结果种将各组的分析结果放在一起进行比较;按组排列输出结果,即单独显示每一分组的分析结果。
选择分组变量
选择数据的排序方式
单击ok按钮,执行操作
(6)计算新变量 在对数据文件中的数据进行统计分析的过程中,为了更有效地处理数据和反映事务的本质,有时需要对数据文件中的变量加工产生新的变量。比如经常需要把几个变量加总或取加权平均数,SPSS中通过【计算】菜单命令来产生这样的新变量,其步骤如下:
选择菜单【转换】→【计算变量】,打开对话框
在目标变量输入框中输入生成的新变量的变量名。单击输入框下面类型与标签按钮,在跳出的对话框中可以对新变量的类型和标签进行设置。
在数字表达式输入框中输入新变量的计算表达式。例如“年龄>20”。
单击【如果】按钮,弹出子对话框。包含所有个体:对所有的观测进行计算;如果个案满足条件则包括:仅对满足条件的观测进行计算。
单击Ok按钮,执行命令,则可以在数据文件中看到一个新生成的变量。
 统计分析软件 IBM SPSS Statistics 26.0 FP001 IF018中文破解版 含教程
统计分析软件 IBM SPSS Statistics 26.0 FP001 IF018中文破解版 含教程
 牙科CAD设计软件 exocad Dental
牙科CAD设计软件 exocad Dental Synopsys CoreTools vW-2024.09-
Synopsys CoreTools vW-2024.09- AviCAD 2025 Pro 25.0.10.5 x64
AviCAD 2025 Pro 25.0.10.5 x64  Synchro plus SimTraffic 12.2.5
Synchro plus SimTraffic 12.2.5 Kenny Asset Forge 2.5.0
Kenny Asset Forge 2.5.0 CPFD Barracuda Virtual Reactor
CPFD Barracuda Virtual Reactor